0 Results for ""
Machine Learning Vs Deep Learning Vs Generative AI


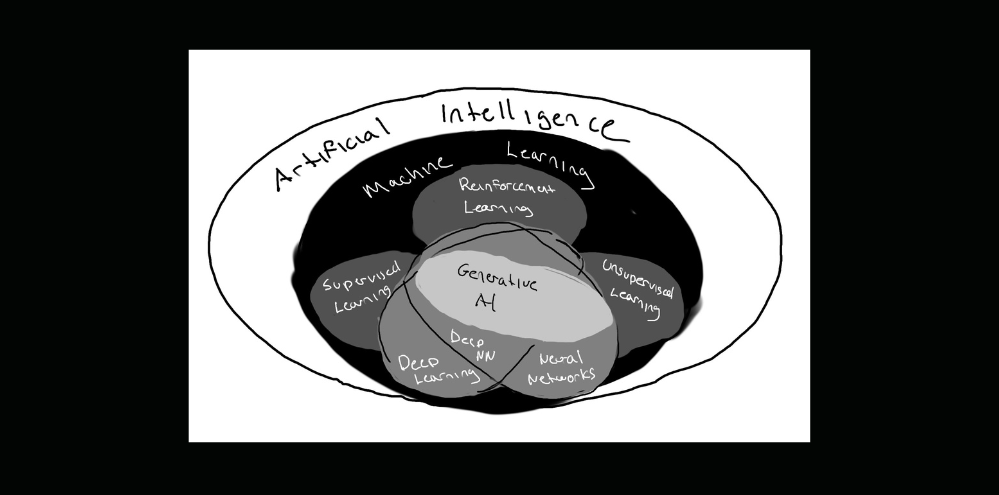
Artificial intelligence has become the catch-all term for any action taken by a computer that we perceive as intellectual. In reality, AI is made up of a subset of techniques applied to solve different types of problems of varying complexity. Neural networks are not only not the answer to every AI problem, but they also aren’t even the primary algorithm for most applications of AI we use today.
The best way to start to understand the difference between these techniques is to understand what it means to learn and apply knowledge. Let’s begin by imagining what it’s like for a young child to find a toy car from the perspective of three AI techniques:
- Machine learning
- Deep learning
- Generative AI
To begin lets look at the different examples and go in detail after about whats happening in each onw.
Machine Learning.
You tell a child: “A car has four wheels, four doors, and it rolls.” Then you walk over to a toy chest, pick up an object with four wheels, four doors, and roll it on the ground. You ask: “Is this a toy car?” The child answers: “Yes.”
In this example, what we’re doing here is giving the child some features (wheels, doors, movement) and adding values that are specific to a car (four doors, four wheels, and it rolls). Good machine learning algorithms will often utilize hundreds of features identified in the data to learn on.
Deep Learning.
Using deep learning, you show a child a series of photos: some with cars (with each photo labeled as “car”) and some that are other objects (with these photos labeled as “not a car”). Now let’s say you manage to show this child 200,000 photos enough so that you feel they’ve seen enough to distinguish between things that are cars and things that are not cars. Once again you go over to the toy chest and bring out a car and ask the child if that is car, hopefully, they say yes again.
What we’re doing here is letting the child make their own determination for the set of features that will identify an object as a car. In this case, it’s hard to know what the child is thinking. Maybe they are looking for blue things to start with because there were lots of blue cars in the photos. Or maybe they decided to make sure the object didn’t have furry legs because dogs were labeled as “not cars”… who knows? Either way, how the child arrived at the result doesn’t really matter as long as the answer is correct.
Generative AI.
Using a generative AI technique, give a child a piece of paper and a pencil, and tell them to draw you a car. Let’s say that this child has never seen a car before, so they start randomly scribbling lines on a paper. You then give each drawing a score out of 10 for how closely it resembles a car. After, say, 200,000 drawings, the scribbles eventually start to resemble a car, and you finally give a 10/10.
Generative AI is like a child going through school from preschool to university. The child improves from some initial foundational learning being applied to solve a problem and then being corrected by a more superiorly informed individual to develop new learnings and knowledge it can apply again—and again.
These examples we just went through are obviously very reductive, but it gives us a foundation to start to explain what exactly is happening here.
Let’s start with a closer look at what’s happening in the machine learning example.
Machine Learning.

Machine learning is a subset of artificial intelligence that also contains deep learning. It primarily relies on utilizing statistical methods to help machines gain experience. One major differentiator from deep learning is that humans often define the features that a machine learning algorithm attempts to learn and understand better as part of the priming and training process. They are essentially complex mathematical functions that can take some input and map it to some output. For this reason, it’s often much easier to visualize what a Machine learning algorithm is doing.
One of the most straightforward examples used to demonstrate how to utilize Machine learning is in estimating home prices. For anyone that has done Andrew Ng’s deep learning course on Corsera, this problem will be very familiar. Homes have several very common “features” such as; square footage, lots size, number of bathrooms, number of bedrooms etc. We can create a model that defines all the features we want to track and train the model to produce a mathematical function that associates these features with the specific house price. A simple visualization would be a regression plot. In a regression plot we would mark a bunch of values for features on an X - Y axis (lets say square footage and home price). Obviously after 3 dimensions it can be hard to visualize but its still easy to follow mathematically - a dimension in a machine learning model is one of the features we alluded to earlier. From there we define a function that produces a line that approximates being as close as possible to the home features in this multidimensional space of features to home price. When when we want our model to estimate the price of a new home the model hasn’t seen before, we provide values for all the features for that home in our function and it returns an output value (a point on the line) that represents the estimated price for those features.

This is why Machine learning models are very common and often more successful than deep learning models in forecasting and underwriting. The functions it produces are deterministic, meaning that they will output the same answer every time for the inputs provided, so there is less ambiguity and therefore are more reliable where precision and consistency are favored. Regression algorithms are not the only techniques used in Machine learning, other common ones are decisions trees, clustering, and vector machines to name a few.
One familiar machine learning experience you feel every day is recommendations: on ecommerce sites, on social media sites, and on content sites. For example, how might Instagram make recommendations for content using machine learning? Well one approach would be to use something like a k-means clustering algorithm where users are clustered together based on common interests (likes cats, trick shots, fashion) and then collaborative filtering can be used to share videos that others in that group watched with the assumption that you might also like these videos. As an individual you can be assigned to multiple clusters based on the various features identified for that group. This is very similar to how recommendations can occur from a variety of your friend groups. Friend groups that have similar interests cluster together and share ideas and products with each other - but your not just part of one friend group, your part of many, and they are all unique or similar based on variety of unconscious characteristics you gravitate towards. This technique is great but we can make it even better with deep learning and will learn how after we learn how deep learning works.
Deep Learning.

Deep learning is often what most are thinking of when they think of AI. Deep learning is best for ambiguous problems where it can be difficult for us as humans to clearly define what the “features” of a problem are, but the output goal can be clearly defined. Neural networks are employed as the primary algorithmic technique because their design allows them to define the features they want in the data that help them achieve the goal (if you want to learn more about how these networks work, checkout my anatomy of a neural network talk). This is why we often say Neural Networks are a blackbox because we don’t really know its feature criteria and the relative importance it associates to the features it identifies.
A relatable example is identifying other cars on the road while driving. A convolutional neural net (CNN) is commonly used in computer vision because it specializes in learning from pixels in an image. When it comes to identifying cars, the old structure of 4 wheels and 4 doors is not as useful when complex orientation and occlusions in the camera’s line of site are present. If we provide a CNN several images and videos of cars - labeled cars - and ones that are not cars – labelled not cars - , with the goal of “identify what a car is” it will start to pick up things in the pictures we never may have thought of on route to identifying what it sees as a car (note: this is what supervised learning is). Eventually it will develop decision pathways that help it understand what a car is from various angles, or light conditions, or even with trees or people in between. Each one of these orientations can represent a pathway in its decision-making process which can several millions of nodes in complex web from input to output. Think of it the same as parts of your brain lighting up when you see a car and that electrical activation makes you say “thats a car”.
The problem with deep learning models is that they are not deterministic, meaning we can’t always guarantee the decision pathway it takes in reaching its output conclusion. Even if the output is correct, it doesn’t always mean the path it took to get there was the same. This is why deep learning models are best when we have some tolerance for variability because as long as the output is in the range of what we want (this is a car, don’t hit it) then we are okay with how it gets there. Deep learning models don’t often do well with precision, but they are powerful tools for solving ambiguous problems. This is why neural networks are employed in language models, we don’t really care if it outputs the same sentence exactly the same every time, we just care that the idea it provides is expressed correctly. This is why they have historically struggled in finance because they can’t be relied upon to output the same numeric value for a set of numeric inputs.
So, how can we use deep learning to improve our Instagram recommendations. A simple way to begin is to use a convolutional net and language model to help label what the video is about. The CNN can create labels to describe things happening at various points in the video and the language model can do the same with the video transcript. The output can then be processed again to get a general sentiment for the video (is it a happy video, educational video, etc). These labels can be used in the machine learning clustering to help further cluster you into more hyper specific groups of interest where collaborative filtering can again, surface videos to recommend within the cluster; i.e cat’s doing silly tricks for food could be a very specific cluster. You can hopefully see why deep learning is better for this because the content of a video can be ambiguous and a label of child climbing a tree vs a tree is being climbed are both equally correct but expressed differently. Yes one label provides more detail than the other and this can often be attributed to how well a model is trained or how specific it needs to be trained to be. You can also use a deep learning model to recommend a particular user to a cluster of videos as well, but this again is more about how you choose to apply the various techniques not necessarily the only way to solve the problem.
Generative AI.

Generative AI first found its identity in 2014 with Generative Adversarial Neural Networks (GANs). The concept authored by Ian Goodfellow was to combine two types of Neural Networks in a novel way. The idea (again very simply) was to incorporate a discriminator neural net that was trained at identifying a specific object (Faces as an example) and a second Neural Network that generated images at random. The generator network creates an image and then it passes it to the discriminator network which then scores how likely it thinks the image is a face. Overtime as the generator neural net crates more images closer and closer to a face it scores higher and higher – until eventually it creates a perfect face. The first major publication on this technique was NVidias PGANs paper in 2016 where a GANs was trained to generate photo realistic images of human faces.
Large Language Models and Stable Diffusion (used for image generation) are significantly more advanced techniques than this generator and discriminator model but understanding how a GANs works is much easier than understanding how ChatGPT or Midjourney work, but you can apply the same foundational principles in your learning journey.
There is a lot of content on how LLM’s work, but to avoid repeating more of it here, instead of focusing on what generative AI can do lets talk about what type of problems this type of model introduces.The major issue with generative algorithms is a regression to the mean, meaning that they often generate average things not the exceptional or unique works that you may want. An easy way to understand this is by applying the normal distribution to the content it is trained on.

The normal distribution (or bell curves for those who experienced those in school) is a naturally occurring phenomena in nature and human creativity is no exception. If we imagine 10,000 essays describing the 2022 US economy, a few will be poorly written, a few will be exceptionally written, and a majority will be of average writing quality. Generative models don’t really have a scoring mechanism for determining what content is better than other content without human feedback. These large models suffer from the same distribution of both the quality of its data ingested and the quality human feedback it receives during reinforcement learning. This is why generative models are still best utilized as assistive tools and are only good replacements for work that requires an average quality of output. This doesn’t mean average is bad, its just stating that in a normal distribution, the average is the middle.
Specialized models training on higher quality curated data reinforced by higher quality humans in the feedback loop will help elevate their performance. Overtime we may see these problems erode as these models learn to train each other with some newly developed scoring functions (this is how AlphaGo improved by playing itself until the student model became the new teacher model and a new student model was spawned to play again and repeat the process). There many other limitations we are discovering about generative models, almost at the same rate new advances are coming out. Its important to understand both sides in order to better anticipate the future.
In conclusion, AI is a spectrum and there are several ways to utilize various techniques of varying complexity. The important take away is that not all AI is built equally and just because something appears simple i.e linear regression, doesn’t mean it’s the inferior algorithm for the problem. The best approach is always to apply the right technique or combination. Often times engineers and companies are bringing a cannon to kill an ant.


.png)